えぬえるぴーや 1ねんせい
- Event:
みんなのPython勉強会#82
- Presented:
2022/06/09 nikkie
BERT以後の自然言語処理入門を話します
いい感じのタイトルは「えぬえるぴーや 1ねんせい」となりました
元ネタは こちら (香川照之さん)
BERTを ばーっと理解 しましょう
皆さんの自然言語処理経験
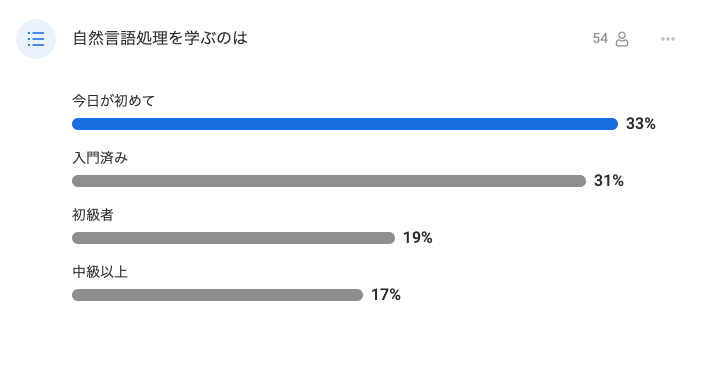
お前、誰よ
えぬえるぴーやの提唱者
電波受信!
— nikkie にっきー シオンv0.0.1開発中⚒ (@ftnext) July 11, 2021
自然言語処理(NLP)に従事する者の呼称、
NLPer(えぬえるぴーや)
SIerと同じ読み方なら、えぬえるぴあー、でも「ぴーや」もそんなに変わらないのでは?
試しに今後のLTなどで名乗って見よう
「ぴーや」(小島よしお)や チキチキバンバン の「ぱりぴーや♪」(パリピ孔明)が好き
このトークの前提
対象は「自然言語処理は初めて・機械学習も初めて」で想定しています
Pythonは入門済みとします(ライブラリを pip install できて、スライドのコード例は手元で実行できる)
注意事項
「私ここ知ってる!」と感じたところは 飛ばして もらってかまいません(通読の必要なし)
自然言語処理・機械学習が初めてでもBERTの一歩目が踏み出せるように構成しましたが、 情報量は多く なっています
理解に時間をかけよう(プログラミングというより物事が出来るようになる思考法)
主な参考書籍
『自然言語処理の基本と技術』(2016)
『BERTによる自然言語処理入門』(2021)
『Pythonによるあたらしいデータ分析の教科書』(2018)
お品書き えぬえるぴーや 1ねんせい
自然言語処理
自然言語処理と機械学習
自然言語処理とBERT
Part I. 自然言語処理
自然言語処理とはなにか
自然言語処理の例
自然言語処理とは
自然言語(Natural Language)を処理する(Processing)
NLP とも呼ばれる
自然言語(📚[1] 1-1)
私たちがふだん書いたり話したりする言語(例:日本語、英語)
人間の歴史の中で 自然 に発達してきた
自然言語ではない言語(📚[1] 1-1)
プログラミング言語
人工言語(例: エスペラント語 )
e.t.c.
自然言語処理(📚[2] 1-1)
自然言語の関わる問題を コンピュータで解く
自然言語処理で扱う 問題=タスク
幅広いタスクがある
例:漢字かな変換(PC・スマホで日本語入力できるのもNLP)
他の例はこのトークの中でも示します
自然言語処理の例
タスク: 感情分析
1つのやり方を示しますが、他のやり方も全然ありえます
感情分析タスク
文書が ポジティブかネガティブか を判定
👉(単純な文書として)この文はポジティブ?それともネガティブ?
極性判定とも言われる
『吾輩は猫である』を感情分析
吾輩は猫である。
名前はまだ無い。
どこで生れたかとんと見当がつかぬ。文で区切られたテキストがあるとします(用意する過程はAppendix)
僕が考えた最強の感情分析ルール(ref: 📚[3] 5.2.5)
文は 単語 から構成される
ポジティブな単語/ネガティブな単語の 数 で文の感情を判断してみる
例:この文は10語からできていて、ポジティブな単語が3、ネガティブな単語が1
ポジティブな単語、ネガティブな単語の一覧
ポジティブな単語、ネガティブな単語の一覧
tsvファイル として読み込む(Pythonのcsvモジュール)
ネガ(経験) あきらめる
ネガ(評価) あざとい
ポジ(経験) あこがれる
ポジ(評価) あか抜ける単語から付与する文の感情スコア
文書の極性= 単語の極性の総和
ポジティブな単語があれば+1
ネガティブな単語があれば-1
(極性辞書にない単語は何もしない)
文の感情スコア例
10語からできた文
ポジティブな単語が 3、ネガティブな単語が 1
感情スコアは+2(
+3+(-1))
『吾猫』の感情分析
ポジティブ・ネガティブな単語の一覧が手元にある(先の辞書)
文も手元にある
どうやって文を単語に分ける?
日本語の文を単語に分ける
日本語は文の中の単語が区切られていない
単語に分けるために 形態素解析 する
形態素解析=単語分割+品詞付与(📚[1] 2-5)
単語分割=分かち書き
品詞:名詞、動詞など
分かち書きの例
吾輩/は/猫/で/ある/。
名前/は/まだ/無い/。
どこ/で/生れ/た/か/と/んと/見当/が/つか/ぬ/。fugashi (MeCab) + unidic の結果
品詞付与のイメージ
ウケる 動詞,一般,,,下一段-カ行,連体形-一般,ウケル,受ける,ウケる,ウケル,ウケる,ウケル,和,"","","","","","",用,ウケル,ウケル,ウケル,ウケル,"2","C1","",849106612396737,3089MeCab + unidic
コンピュータで形態素解析
MeCab
Pythonライブラリ
「オープンソース 形態素解析エンジン」MeCab
言語, 辞書,コーパスに依存しない汎用的な設計
mecab コマンドで単語分割と品詞付与できる
Pythonで形態素解析
ライブラリにより、 Pythonから MeCabを使える
fugashiを紹介(ラッパーライブラリ)
fugashi による分かち書き
from fugashi import Tagger
tagger = Tagger("-Owakati")
texts = ["吾輩は猫である。", "名前はまだ無い。", "どこで生れたかとんと見当がつかぬ。"]
for text in texts:
print("/".join(word.surface for word in tagger(text)))付与する品詞情報の利用例
文中の単語は活用されている(例:ウケた)
品詞情報を使って、辞書に載っている形式= 原形に戻せる (例:ウケる) ※極性評価辞書の関係
今回はunidicという辞書を使っています
原形に揃える例
我が輩/は/猫/だ/有る/。
名前/は/未だ/無い/。
何処/で/生まれる/た/か/と/うんと/見当/が/付く/ず/。fugashi (MeCab) + unidic の結果
参考 fugashi で原形に戻して分かち書き
from fugashi import Tagger
tagger = Tagger("-Owakati")
texts = ["吾輩は猫である。", "名前はまだ無い。", "どこで生れたかとんと見当がつかぬ。"]
for text in texts:
print("/".join(word.feature.lemma for word in tagger(text)))極性辞書の都合で、原形が必要
ルールを決めて『吾輩は猫である』の文を感情分析
形態素解析 で文を単語に分ける
日本語極性評価辞書を読み込む
ポジティブ/ネガティブな 単語を数えて 文の感情スコアとする
『吾輩は猫である』の感情分析結果
# 0
吾輩は猫である。
名前はまだ無い。
どこで生れたかとんと見当がつかぬ。
# ポジティブ 3 (まあわかる)
これは背のすらりとした撫肩の恰好よく出来上った女で、着ている薄紫の衣服も素直に着こなされて上品に見えた。
# ポジティブ 3 (あれ?)
背といい毛並といい顔の造作といいあえて他の猫に勝るとは決して思っておらん。
# ネガティブ -2 (まあわかる)
死んでからああ残念だと墓場の影から悔やんでもおっつかない。まとめ🥟 Part I. 自然言語処理
自然言語の関わるタスクをコンピュータで解く
文の構成要素である単語を扱う例
形態素解析=分かち書き+品詞情報
Part II. 自然言語処理と機械学習
自然言語処理における機械学習
機械学習を使った自然言語処理の例
自然言語処理における機械学習
自然言語処理のタスクはコンピュータで解く
機械学習の機械=コンピュータ
タスクへのアプローチの変化
吾猫の例で示したのは 人手 🙋♂️によるルールを使ったアプローチ
ルールをデータから見つける技術である 機械学習 も使われる
機械学習について簡単に(📚[3] 1.2.1)
大量のデータから、機械学習アルゴリズムによってデータの特性を見つけて予測などを行う計算式の塊を作る
機械学習について簡単に(📚[3] 1.2.1)
作られる計算式の塊= モデル
モデルを作る(=訓練する=ルールを 自動 で求める)ために
大量の データ を用意
機械学習アルゴリズムを指定
自然言語処理のタスクは、機械学習でいう 分類 タスク
教師あり 学習:データに 正解ラベル がある
正解ラベルは カテゴリ
この後出す例:ニュースグループのカテゴリ(宗教、コンピュータ、など)
教師あり学習(分類も該当)
モデルで予測したい変数(=目的変数)は 正解ラベル
特徴量 (=説明変数)を使って、モデルを訓練
※機械学習の用語の説明は📚[3] 1.2.3をどうぞ
機械学習でテキストを扱うには(📚[2] 1-2)
テキストからタスクを解くのに有用な特徴量を抽出する
テキストを数値に変換 する必要がある(次で例示)
特徴量でモデルを訓練
補足:自然言語処理の歴史(📚[1] 1-3)
自然言語処理はコンピュータが誕生した1940年代からある(翻訳)
当初は 人手 🙋♂️でルールを整備(≒if文いっぱい)
1990年代から、 機械学習 🤖を用いたアプローチ(統計的自然言語処理)が登場
機械学習を使った自然言語処理の例
タスク: 文書分類 (テキスト分類)
ニュースグループの投稿(英語)をカテゴリに分類する
脱線:ニュースグループって?
ネットニュースのグループ
ネットニュース≒電子掲示板
「今で言うTwitterみたいなものね」
ニュースグループの投稿をカテゴリに分類
scikit-learnのチュートリアル Working With Text Data から
機械学習アルゴリズムや評価用ツールが集まったライブラリ(📚[3] 1.3.2)
機械学習でモデルの訓練に必要なものは
データ
機械学習アルゴリズム
機械学習でモデルの訓練に必要なものは
データ:ニュースグループの投稿(
sklearn.datasets.fetch_20newsgroups)機械学習アルゴリズム:ニューラルネットワーク(
sklearn.neural_network.MLPClassifier)
機械学習でテキストを扱う流れ
テキストから特徴量を抽出(テキストを 数値 に変換)
特徴量でモデルを訓練
データから特徴量を抽出
テキスト(=文書)= 文 の集合
個々の文は 単語 から構成される
テキストに含まれる単語を使って、テキストを数値で表す
テキストを単語に関する数値で表す(📚[3] 5.2.3)
2つのテキスト
子供が走る
子供の脇を車が走る
単語:子供/走る/車/脇/が/の/を
テキストを単語に関する数値で表す(📚[3] 5.2.3)
子供が走る
テキストを構成する単語 子供/走る/が に何らかの数値
このテキストに登場しない 車/脇/の/を は0で表す
(子供/ 走る /車/脇/ が /の/を) = (? / ? /0/0/ ? /0/0)
テキストを単語に関する数値で表す(📚[3] 5.2.3)
子供の脇を車が走る
テキストを構成する単語 子供/走る/車/脇/が/の/を に何らかの数値
(子供/走る/車/脇/が/の/を) = (?/?/?/?/?/?/?)
文中の単語の数値を算出
単語の TFIDF を使う
正の小数値
テキストに 特徴的 な(=多く登場し、かつ、そのテキストにしか登場しない)単語には大きい値
ニュースグループ投稿のテキスト分類
分類するカテゴリは4つ
ニュースグループの投稿のうち 2257 本を扱う
含まれる全ての 単語 は 35788 語
TFIDFで特徴量抽出
1つ1つの投稿は、35788個の数値の並びで表される(ベクトル)
投稿に含まれる単語はTFIDFの値、含まれない単語は0
TFIDFで特徴量抽出
例: 'OpenGL on the GPU is fast'
gpu god opengl ... (35000語分並ぶ)
0.67 0 0.60openglやgpuはこのテキストに特徴的ということ
特徴量でモデルを訓練
特徴量:2257本 × 35788個の数値 & 正解ラベル
教師あり学習の設定で、モデルを作る
= 特徴量から投稿分類ルールを自動で求める
モデルの気持ち
このカテゴリは、これらの語のTFIDFが高いぞ!
別のカテゴリは、別の語たちのTFIDFが高いぞ!
ただし、機械学習は、ルールを適用した結果、 間違える可能性 がついて回ります
コード例
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.neural_network import MLPClassifier
categories = ["alt.atheism", "soc.religion.christian", "comp.graphics", "sci.med"]
twenty_train = fetch_20newsgroups( # ニュースグループの投稿4カテゴリ分(正解ラベル付き)
subset="train", categories=categories, shuffle=True, random_state=42
)
tfidf_vect = TfidfVectorizer()
X_train_tfidf = tfidf_vect.fit_transform(twenty_train.data) # TFIDFで特徴量抽出
clf = MLPClassifier()
clf.fit(X_train_tfidf, twenty_train.target)モデルの実力、見せてもらおう!
短い投稿をモデルで分類してみます
'God is love' -> soc.religion.christian
# 宗教カテゴリに分類された
'OpenGL on the GPU is fast' -> comp.graphics
# コンピュータカテゴリに分類された英語と日本語の違い
英語は 空白で単語が区切られて いる
そのまま
sklearn.feature_extraction.text.TfidfVectorizerに入力できる
日本語ではまず単語を区切る必要がある(先に示した 分かち書き)
まとめ🥟 Part II. 自然言語処理と機械学習
タスクを解くために、人手のルールだけでなく、機械学習( データからルールを見つける技術 )を使う
機械学習では、人手で抽出した 特徴量 からモデルを訓練
TFIDFで特徴量を作る例
Part III. 自然言語処理とBERT
(今日のstapyと)最近の自然言語処理を席巻している BERT がいよいよ登場します
Part III. 自然言語処理とBERT
BERTに至る流れ
BERTの訓練 101
BERTの利用例
ニューラル言語モデル
ニューラルネットワーク により実現される
言語モデル
ニューラルネットワーク(📚[2] 2-2)
機械学習アルゴリズムの1つ(先に示した)
変換を行う層 を(何層も) 組合せる
言語モデル(📚[2] 2-1)
文章の 出現しやすさ を確率によってモデル化
「私はパンを食べた」>「私はパンに食べた」>「私は家を食べた」
この確率は文章の 自然さ とも見なせる
ニューラル言語モデルの訓練
言語モデルとなるニューラルネットワークを訓練する
自然言語から ラベル付きデータを自動で作れる
例:それまでの単語たちから次の単語を予測
ニューラルネットワークへの入力
単語を 整数ID に変換だけして入力
例:
7184, 30046, 9, 6040, 12, 31, 8
各単語(ID)をどのようなベクトルとして扱うかも自動で見つける
用語紹介「深層学習」(📚[2] 1-3)
1つのモデルで特徴量抽出とその後の処理を行う
特徴量の抽出も含めて、データからルールを 自動 で見つける
人手によらない特徴量抽出
BERT
ようやくBERTの話ができる!(ゼイゼイ)
Transformer(📚[2] 3-1)
2017年の論文「Attention is All You Need」で提案されたモデル
BERTはTransformerで提案されたニューラルネットワークを用いる
BERT
2018年発表、Bidirectional Encoder Representations from Transformersの略
BERTもニューラル言語モデル
1つのモデルで複数のタスクを扱える のが革新的
余談:BERTは コンビニ
NLP2022チュートリアル で聞いた喩え
BERTは汎用モデルで、かつタスク固有のモデルを凌いだ
BERT(コンビニの鰻・天ぷら)/タスク固有モデル(鰻屋の鰻・天ぷら屋の天ぷら)
ライブラリ transformers 🤗
Transformerやそれ以後に派生したモデルを扱うためのライブラリ
Transformerモデルの 訓練 や、 読み込んで使う のをサポート
もちろんBERTもサポート
BERTの利用例:感情分析タスク
『吾輩は猫である』の感情分析をBERTでやってやりましょう
感情分析タスクは、機械学習の 二値分類 (2つのカテゴリに分類)
コードはこれだけ!
from transformers import pipeline
nlp = pipeline(
"sentiment-analysis",
model="daigo/bert-base-japanese-sentiment",
tokenizer="daigo/bert-base-japanese-sentiment",
truncation=True,
)
texts = ["吾輩は猫である。", "名前はまだ無い。", "どこで生れたかとんと見当がつかぬ。"]
for text in texts:
print(nlp(text))BERTによる感情分析結果
吾輩は猫である。
-> [{'label': 'ポジティブ', 'score': 0.9909781217575073}]
名前はまだ無い。
-> [{'label': 'ポジティブ', 'score': 0.5273743867874146}]
(ネガティブが0.47なので、自信がない)
どこで生れたかとんと見当がつかぬ。
-> [{'label': 'ネガティブ', 'score': 0.9475129842758179}]コードの裏で行われていること
日本語の感情分析BERTの ファイル群 をダウンロード
ファイル群をモデルや トークナイザ として 読み込む
トークナイザとは
「単語どうしを区切る」役割
ただし、単語(word)よりも細かい単位(サブワード)で区切ることがある
>>> nlp.tokenizer.encode("吾輩は猫である。") # トークナイザによりIDの並び
[2, 7184, 30046, 9, 6040, 12, 31, 8, 3]
>>> # decodeすると 吾輩/は/猫/で/ある/。 と分かち書きされたBERTの訓練を押さえよう
例を見たBERTについて 理論面を少しだけ
これだけ押さえる: 転移学習
訓練が2段階ある
事前学習(pre-train)
ファインチューニング(fine-tuning)
事前学習
大量のテキストを用意(日本語で書かれたWikipedia)
(簡略化して言うと)テキスト中の単語を 穴抜け にして、その単語を推測させて訓練
穴抜けにすることで、大量の教師データを確保
事前学習
計算コストはめちゃかかる(一例: TPUを使って5日間)
誰かが一回 やればOK
事前学習済みのモデルがトークナイザと一緒に 公開 されている(例:東北大学乾研究室)
IMO:事前学習済みのモデルのイメージ
「こいつ、日本語わかってるな」
分かっているように見える例はすぐ後で
ファインチューニング
事前学習済みモデルを 手元のデータで再訓練
解きたいタスク向けにチューニングするイメージ
ファインチューニング
解きたいタスク用のデータ(少量 でよい)を使って各自やる
計算コストはそんなにかからない(Colabを使う例を紹介)
ファインチューニング済みのモデルも公開されている(感情分析の例で利用済み)
も〜っと!BERTを使おう
事前訓練済みのBERTを使う
ファインチューニングされたBERTを使う(済み)
ファインチューニングする
事前訓練済みのBERTを使う
今回は、東北大乾研究室が公開している日本語BERTを使います
テキスト中のマスクした単語を埋めるタスク
これはBERTの事前訓練で使った形式(単語がマスクされる)
私は[MASK]を食べた
私はパン[MASK]食べた
事前学習済みの日本語BERTでマスク埋め
from pprint import pprint
from transformers import pipeline
nlp = pipeline("fill-mask", model="cl-tohoku/bert-base-japanese-v2")
pprint(nlp("私は[MASK]を食べた"))
pprint(nlp("私はパン[MASK]食べた"))トンチンカンな埋め方しない!
私は[MASK]を食べた
それ
肉
パン
これ
魚
私はパン[MASK]食べた
を
も
ばかり
まで
だけこいつ、日本語わかってるなって思いませんか?
ファインチューニングする
オススメのファインチューニングアプローチ
transformersリポジトリにある examplesスクリプト を利用
コードを書かずに ファインチューニングできます(ref: NLP2022 チュートリアル)
モデル自体を定義するアプローチもありますが、nikkieはあんまりやりません(車輪の再発明はしないという立場)
コードを書くケース
examplesスクリプトが想定している形式にデータを 変換 するためのコードは(必要なときだけ)書きます
ファインチューニング例
token-classification(トークンに関する分類)
トークン=文の構成要素(単語もしくは単語より小さいサブワード)
固有表現抽出(NER)
トークンが 固有表現 か分類
固有表現:固有名詞(人名・地名など)や日付・時間・金額(📚[1] 7-1)
人名や法人名など複数のカテゴリがある
日本語BERTをファインチューニング
-
データ https://github.com/stockmarkteam/ner-wikipedia-dataset の形式だけ加工
transformersのexamplesスクリプトを実行
固有表現抽出するBERT
ライオンって動物だったり、会社だったりしますよね?
ライオンは、哺乳綱食肉目ネコ科ヒョウ属に分類される食肉類。
# -> 固有表現は抽出されない
# Wikipediaの記載 https://ja.wikipedia.org/wiki/%E3%83%A9%E3%82%A4%E3%82%AA%E3%83%B3
日々の暮らしの中で使用される数々の製品を通してお客様との接点を持ち、生活を理解していることはライオンの強みです。
{'entity': 'B-法人名', 'score': 0.98595715, 'index': 30, 'word': 'ライオン', 'start': None, 'end': None}
# ライオン株式会社サイト中の文言 https://www.lion.co.jp/ja/まとめ🥟 Part III. 自然言語処理とBERT
BERTは 複数 のタスクを扱えるモデル!(性能もよい)
ライブラリ
transformersを使って公開された モデル の利用
事前学習済みモデルを ファインチューニング
まとめ🌯 えぬえるぴーや 1ねんせい
自然言語処理の流れ、人手のルール➡️機械学習➡️深層学習(特徴量もルールもデータから抽出)
BERTは複数のタスクを扱え、性能もいいモデル
transformersで少ないコードで利用・ファインチューニング
ご清聴ありがとうございました
Happy NLP with BERT!
TODOs
Reference(主な参考書籍+α)
Appendix