XPで取り組むMLOps
XP(エクストリームプログラミング)
2023/03/09 第29回MLOps勉強会 nikkie
イントロダクション
自己紹介
開発チーム紹介
XP紹介
おことわり
お前、誰よ
ふたつぎ at ユーザベース
データサイエンティスト(2019〜)
自然言語処理、機械学習、テスト駆動開発、ペアプロ、たーのしー!
ユーザベースには、2つの開発チーム
BtoB向けSaaSプラットフォームの開発チーム 🙋♂️
ビジネスパーソン向けメディアサービスの開発チーム
BtoB向けSaaSプラットフォームの開発チーム
1つの開発チームに4つの職種
例:データサイエンティストとソフトウェアエンジニアが 同じチーム
以降では「開発チーム」=「BtoB向けSaaSプラットフォームの開発チーム」
こんなチームで働いています(異能は才能)
『評価指標入門』の著者はじめ、いろんな強みを持つデータサイエンティストと働いています!
全社週1で知見共有: ユーザベースのデータサイエンティストが集まる社内勉強会を振り返ります!
XPって、何よ
XP(エクストリームプログラミング)で取り組むMLOps
私たち(SaaSプラットフォームの開発者)は
エクストリームプログラミング を実践しています
アジャイル開発
2001 アジャイルソフトウェア開発宣言
発表者はウォーターフォールもアジャイルも経験しています
アジャイル開発の手法
1手法として、XP (エクストリームプログラミング)
他の手法として、スクラム など
nikkieは入社するまで「XPは聞いたことがある」程度でした
チーム開発
アジャイル宣言の背後にある原則 でもチームに言及
私たち開発チームの考え方:成果を出す最小単位はチーム
加えて「個人が強くなったらなお最強じゃん」
XP(極限プログラミング?)
目的は 圧倒的なソフトウェア開発の実現 (創始者 ケント・ベック氏)
通常の開発プラクティスを 極限(エクストリーム) まで推し進める
XPの3要素
価値 (values):抽象的・普遍的な判断基準
プラクティス (practices):日常的な取り組み
この2つを 原則 (principles)が橋渡し
この発表では プラクティス にフォーカス
再掲)通常の開発プラクティスを極限(エクストリーム)まで推し進める
IMO 思うに 習慣 (参考)
サークルオブライフ (12のプラクティス)
サークルオブライフ
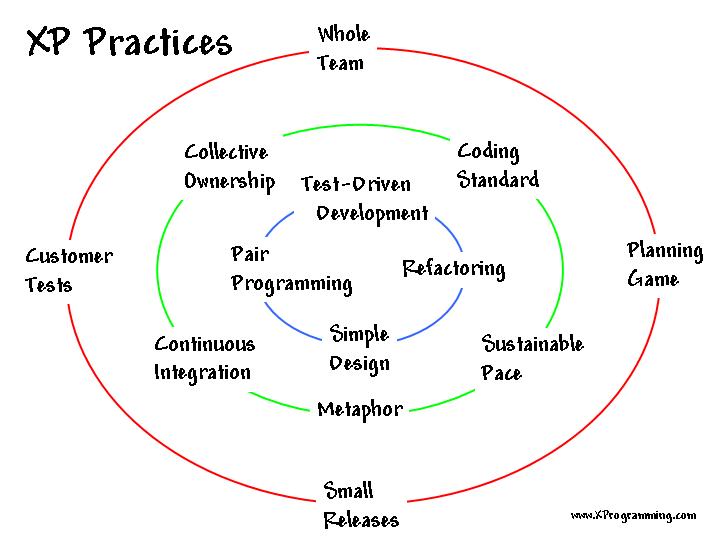
ロン・ジェフリーズ氏がXPのプラクティスを描いた図
3つの円、計12のプラクティス(習慣)
外側の円(赤):ビジネス向け 4つ
真ん中の円(緑):チーム向け 4つ
内側の円(青):開発者向け 4つ
XPのエッセンスとなる5プラクティス(by 角さん)
ペアプログラミング
テスト駆動開発・リファクタリング
シンプルな設計
受け入れテスト
私たちデータサイエンティストも実践しています
日常的に、ペアプログラミング・テスト駆動開発
シンプルな設計・リファクタリング
受け入れテスト(APIのE2Eテスト)
いくつか、おことわりを
3点共有
1 "データサイエンティスト"
「自分もデータサイエンティストだけど、発表者とは職務内容がちょっと違う?」
ここまで聞いてこういった感想、あると思います
目的は、 事業に価値を 提供すること
機械学習、自然言語処理等の技術を利用して、ユーザベースが展開するB2B SaaSプロダクトの価値を高める (求人ページ)
IMO:この場に集った私たち参加者はこの目的を共有している!
お互いに学び合いましょう
ポイントは 読み替え だと思います
勉強会での発表を読み替えて知見を見出すの、私、大好きなんです
自分の文脈に読み替えてヒントがあったら幸いです
私たちは、他者の実践の背景にどんな状況、制約があったのかを理解し、自分たちの状況、制約の下ではどのように実践するべきなのか捉え直さないといけない。
『カイゼン・ジャーニー』(Kindle の位置No.231-233)
2 機械学習システムに ソフトウェアエンジニアリング でアプローチ
SaaS事業の開発チームの現在のやり方
GoogleのRules of Machine Learningにも
do machine learning like the great engineer you are, not like the great machine learning expert you aren't.
Overview より
3 小さなリリース を積み重ねた半ばです
この場で話すのは現時点の 暫定解 (日々格闘中です!)
小さいリリースを重ねた中での到達点であり、今後に続く小さなリリースの中で更新される
MLOps事例紹介
データサイエンスの課題設定
XP で取り組むMLOps事例紹介(2つ)
目指しているもの も紹介
SaaS事業におけるデータサイエンス
経済情報を使ったプロダクト
SPEEDA
FORCAS
INITIAL
etc
経済情報
企業情報
ニュース
業界(独自定義)
etc etc
SaaS事業の課題設定
企業 の 業界 推定(マルチラベル分類。こちらをメインに紹介)
ニュース に 企業 紐付け(固有表現抽出)
etc
企業の業界推定(マルチラベル分類)
企業情報1000万社(国内・海外、上場・非上場)
ユーザベースのアナリストが、独自定義した業界(560業界)の中から選定
教師あり学習して 機械学習モデルで業界推定 する
事例1 日々の開発
パイプライン
基本コンポーネント
パイプラインとは、インフラストラクチャ
The infrastructure surrounding a machine learning algorithm.
https://developers.google.com/machine-learning/guides/rules-of-ml?hl=en#terminology
念のため、scikit-learnの Pipeline ではないです
2つのパイプラインを実装
モデル 訓練 パイプライン:データ取得〜モデル訓練&出力
モデル リリース パイプライン:訓練したモデルをAPIとしてリリース
技術スタック 1/2
モデル訓練:scikit-learnやPyTorch
API化:FastAPI
APIやパイプラインの各処理はKubernetesで動かす(Dockerコンテナ化)
補足:マイクロサービス
開発チームは、マイクロサービスアーキテクチャを採用
データサイエンティストは、機械学習モデルを作るだけでなく、他の開発者が使えるように APIとしてリリース までやる
技術スタック 2/2
パイプラインの実体はJenkins
JenkinsからKubernetesクラスタにJobやDeploymentを作成する
kubectl コマンドをAnsibleでラップ
モデル訓練パイプライン
データ取得
データ加工
学習
ボタン1つで、モデル訓練!(Automation🙌)
ボタン1つで最新データを取得してモデルを訓練できる
最初から最後まで通してだけでなく、途中からの実行もできる(モデルだけ作り直す)
モデルリリースパイプライン
訓練パイプラインで作ったモデルをAPIとしてサーブ
blue-green deployment(弊社テックブログ)により、簡単に切り戻せる
課題設定ごとにパイプライン
企業の業界推定(マルチラベル分類)モデル 訓練 のパイプライン
ニュースの企業紐付け(固有表現抽出)モデル 訓練 のパイプライン
モデルをAPIとして リリース するパイプライン
パイプラインの中の実装
開発しているのは 再利用可能な基本コンポーネント
IMO:ライブラリ開発に近い
基本コンポーネント開発
解きたい課題は無数に出てくる
イメージ:企業・ニュース・業界 -> ニュースの業界推定 (NEW!)
データが違えば違う問題が解ける ようにしている
基本コンポーネントの利用
前述のパイプラインの各ジョブの実装
モデルの精度を追い求めるR&Dでも利用(パイプライン活用)
閑話休題🍵 お前、誰よ(コミュニティ編)
特にPythonコミュニティで にっきー(nikkie) として知られる
Python Conference JP 2021 座長
最近は 毎日1エントリ 書いてます(100日超えました🙌)
目指しているもの
「XPで取り組むMLOpsでこれを実現したい!」
現時点のもの
再びのサークルオブライフ
プラクティス(習慣)「小さなリリース」
=小さい(ごく小規模な)リリースを 頻繁 に
サークルオブライフでは Small Releases (赤の円の下)
リリースしやすい状況を作れている!
パイプラインによりボタン1つでリリース
リリースは開発で自由にできる。デプロイ(ユーザに届ける)はビジネス判断という切り分け
「小さなリリース」の前提条件
小さなリリース=継続的デリバリー
変更するたびに本番環境にコードをリリース
(今)目指している状態: CD4ML
"機械学習の継続的デリバリー"
Hidden Technical Debt in Machine Learning Systems (2015, Google) を受けて
私たちの考え
時間をかけてめちゃめちゃいいモデルを作ってデプロイは私たちはしない
めちゃめちゃよくなくても、ビジネス価値のあるモデル ができ次第、デプロイ
その後も良くしていく(評価指標がカイゼンしたらリリース)
事例2 小さなリリース
XPの価値の1つ:フィードバック
ゴールに近づくためにフィードバックを使う
データを使って事業に価値を提供したい!
でも、最初はそのやり方が、わかんない!
できるだけ 多く のフィードバックを生み出す
かつ、できるだけ 早く
プラクティス(習慣):小さなリリース
小さい単位 でフィードバックを得る
小さい単位であれば、1回あたりは早く、繰り返すことで多く、フィードバックを得られる!
フィードバックから 学ぶ (学びが多いだけゴールに早く近づける!)
余談:イメージは勾配降下法
『継続的デリバリーのソフトウェア工学』4章(IMO:この本はアジャイル開発のすばらしい本!)
小さく=
batch_size?
プラクティスは練習で身につける!
小さなリリース= いつでもリリースできる ように開発を進める
最初は全然うまくできませんでした(テスト駆動開発もペアプログラミングも全部)
例:ハイパーパラメタの探索
範囲を絞る➡️具体値と決めていく
評価指標はすでに決めてある
範囲を絞ったら、そこでリリース!
実験して範囲が絞り込まれた(
10 ** -N)評価指標から今リリースしているモデルよりよい(better)と言える
そのハイパーパラメタでモデルを訓練してAPIリリース
リリースのタイミングを 何回も 作った
範囲が決まった後は、評価指標の値がよりよくなる値を見つけ次第、再びリリース
めちゃめちゃ時間をかけて探索して1回だけリリースという進め方はしませんでした
リリースのタイミングを何回も作った結果
範囲を探索してリリースした後、 具体値の探索はしていない
代わりに、より価値の高い開発へ移れた!
小さなリリースのメリット:一部でも価値を届けた状態で 方向転換 もできる
参考:Release Early, Release Often
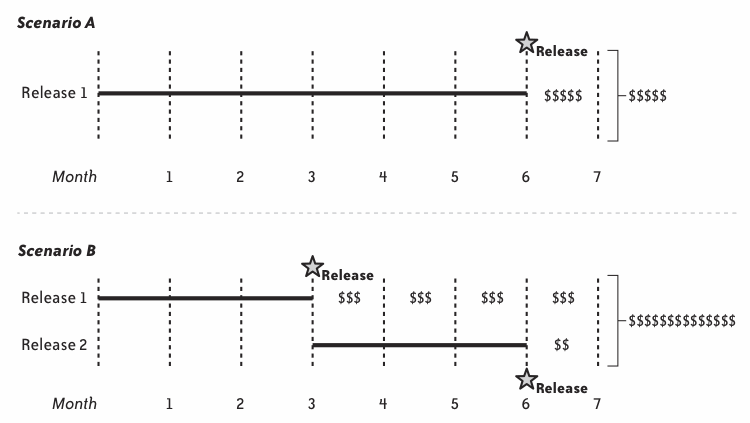
『アートオブアジャイルデベロップメント』原著初版公開版より
別の例:賢い 小さい機能
小さい機能を一から作る
機械学習を使うとうまく作れそう(賢さ)
ユーザは社内
リリースのタイミングを 何回も 作った
ルールベース + システム開発 で小さい機能を作りきってリリース
単純なモデル + 訓練に使うコード を次に作ってルールベースを置き換えてリリース
モデルもシステムも一度に全部作ることはしませんでした
ゼロから作る 機械学習を使った機能
一からシステム開発するのは重い
システムをまず作りきる
機械学習を使いたい部分は最初は優先度を下げてルールベース
ルールベースから機械学習への切り替え
機械学習モデルのパイプラインの作成も重い
パイプラインを作り切る のを優先(モデルは優先度を下げて単純にする)
ルールベースを置き換えることで、モデルをシステムに組み込むAPIも固まる
その後、複雑なモデルを試していき、性能が向上したら置き換える
小さく何度もリリース!
複数回のリリースのオーバーヘッドより、リリースを繰り返したほうが早い(当社比)
小さなリリースをするための考え方のコツ
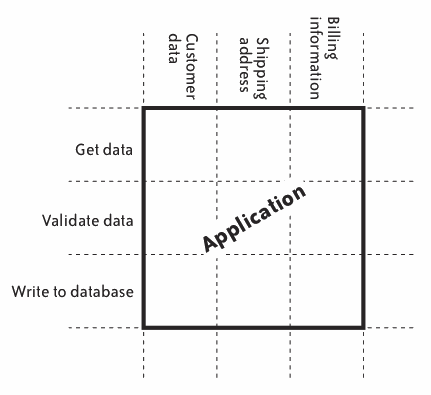
縦スライス(横スライスではなく)
何回もやる
横スライス(賢い小さい機能を例に)
システム部分を作る
単純な機械学習モデルを使う部分を作る
部分ごとに作っていき、これらが 全部終わって初めてリリース できる
縦スライス
限定的なもの を作って繰り返しリリースするという考え方の転換
各スライスはそれ単体でリリースできる(練習あるのみ!)
モデルの性能を限定して、薄く全部作る(ルールベースや単純なモデル)
参考:横スライスと縦スライス
何回もやる(1周、2周、3周、...)
1周目はゼロから作るので重い。小さく絞る
2周目以降は1周目でできているものが使える
何回もやる
2周目以降の生産性が上がるように意志を込めて選ぶ(例ではシステムを優先した)
"イテレーション"=反復するので、とくに序盤は 常に次がある (何回も繰り返した末に完成すればいい)
まとめ🌯:XPで取り組むMLOps
ユーザベースのデータサイエンティストのMLOps事例を共有
XPのプラクティスを実践してMLOpsしています
日々の開発
XPのプラクティス:ペアプログラミング・テスト駆動開発・etc
基本コンポーネント・パイプライン開発
小さなリリースの反復
フィードバックを頻繁に得て学びながら進みたい!
ハイパーパラメタ探索や機械学習を使った機能開発で小さく何度もリリースした事例を共有
(今)目指すもの:CD4ML
ご清聴ありがとうございました
なにかヒントがあったらとても嬉しいです
プラクティスは裏の考え方(原則・価値)を知ると、読み替えやすいですよ〜(XP沼へようこそ)
Appendix
TODO: ここに参考文献リンク